Model Train-related Notes Blog -- these are personal notes and musings on the subject of model train control, automation, electronics, or whatever I find interesting. I also have more posts in a blog dedicated to the maintenance of the Randall Museum Model Railroad.
2022-02-13 - Conductor 2: Sequence Manager and Block Graph
Category Rtac
Conductor 2 is organized around the concept of routes, and each route as “manager” which defines its behavior. Upfront, I envision 3 types of route managers: idle (does nothing), sequence (aka shuttle mode), and window (a “free” algorithm better suited for continuous runs).
Right now we’ll focus on the sequence manager, for shuttle operations.
When exploring the DSL concept for the Conductor 1 extension, the suggestion is to have a block “list”, and a separate set of rules didcating action rules when the train enters specific blocks. It’s important to realize there’s a disconnect as the rules are not strictly attached to the blocks in the block list. We track the active block in the block list, which has no rules attached to it. So how do we find the corresponding actions? Since this is a shuttle, we only need to know the block and engine direction to know which set of rules to apply.
By comparison, when I started exploring the Groovy DSL, I used the “other” obvious implementation: the route is a list of blocks and their travel direction and their associated action rules. In this case, since we track the active block in the list, it is obvious which rules should be applied.
One thing I realized, as discussed in a previous post, is that specifying the travel direction in the block list is irrelevant. In short, that’s because we always progress linearly in the block list, no matter what, and the travel direction is the result of throttle actions, it is not controlled by the manager. The manager expects the script to do “the right thing” and correctly control the train to move from the currently active block to the expected next block. We will use the next block’s sensor as a signal that has happened, however we will not use the travel direction. Thus if that information is useless to the manager, it should not be specified in its block list.
It’s important to realize this is due to our underlying sensor structure -- we use track block sensors which detect presence at certain points but not direction. It’s possible we could have a different command station that can use an enhanced DCC/LCC protocol to detect both the location and the direction of a train. In that case, would it be relevant to have the direction? If we ever get there, we’ll likely want to have a dedicated manager handling this. There’s another problem with encoding the direction in the graph, which we’ll discuss below.
In that case, that means the block list can be described as a list of blocks and their associated rules. The rules are executed as long as this is the active block -- exactly as if each rule were prefixed with a “block active” condition. That applies to any time-delayed action. If the script needs any timed action to be executed after the train has left the block, that rule must be someone coded outside of the block’s rules.
The Groovy DSL version where the block list also describes the actions for each block has pros and cons. The pro side is that it’s easier to see which rules would be applied to that active block. The cons side is that it makes the block list hard to read since it’s interseeded with all the action rules. It removes the concise “block order” declaration from the Conductor 1 syntax.
Problem 1: It’s a graph, not a list.
Now we have not addressed the one elephant left in the room. In the previous post, I made a point of explaining we need a graph, not a linear list. Thus we need to tackle the issue of describing that in a text file. How?
Whether we’re dealing with Conductor 1’s simple block list, or the Groovy DSL with blocks and their actions, a list is an easy construct: a couple square brackets and a comma-separated list of whatever items we need. The syntax is easy. A graph in a text file is a bit more dubious to represent.
My immediate thought was “graphviz dot language” (https://graphviz.org/doc/info/lang.html). Here, a directed graph look like this:
A -> B
B -> {C, D}
I haven’t exactly used graphviz a lot. The syntax was OK and intuitive, even though not the most readable as things get a bit terse when the graph grows many branches.
In our case, we have the issue that our graphs are going to be mostly lists, so maybe we should optimize the syntax for the simple case. Going back to the previous example:
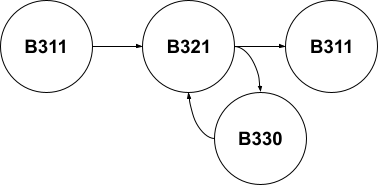
An obvious clear way would be to write it as such:
B311 -> B321 -> { B330, B311 }
B330 -> B321
We could try to express the fact that our route is “mostly” linear, by trying to express that we have an “optional” sub-route, kind of like a regexp, but it gets clunky:
B311 -> B321 -> { B330 -> B321 }? -> B311
Or maybe we can simply do this:
B311 -> B321 -> B311
B321 -> B330 -> B321
The way to read the latter is to construct the first “linear” graph, and then “merge” the branches from the second one. The latter syntax as the advantage that it can easily be represented using the semantic of comma-separated list in most text-based languages:
Route.blocks = [ [ B311, B321, B311 ],
[ B321, B330, B321 ] ]
Ironically if we do that, we then need to forgo the ability to declare action rules right in the block graph declaration, and we’re back to Conductor 1’s paradigm of separating the graph description and the rules. That’s because in this case, we have specific blocks appearing multiple times. We could of course only declare action rules for one of these instances (or merge them together), but that would likely be confusing. A script writer could easily be confused and think there are 3 instances of B321 which could be active, each with their set of rules, yet in fact all these would be merged together.
Problem 2: Nodes in the graph are ambiguous.
Let’s test the limits of that syntax. What if I want to write a “shortcut” in my shuttle. Say I have 5 blocks but sometimes I can throw a turnout and bypass multiple blocks? E.g. something like this:
B01 -> B02 -> B03 -> B04 -> B05 -> B04 -> B03 -> B02 -> B01
B01 -> B04 -> B05 -> B04 -> B01
Here we have maybe a double track and one side has 2 blocks which the other one doesn’t yet they go to the same place. We can rewrite it as such:
Route.blocks = [ [ B01, B02, B03, B04, B05, B04, B03, B02, B01 ],
[ B01, B04 ],
[ B04, B01 ] ]
There is one obvious problem though, which is that we have 2 occurrences of B01 and B04 in our graph, and that does not indicate which ones we branch from… is that the leading one or the reversing ones?
That’s where ironically having the engine direction in the block graph would help us distinguish them:
Route.blocks = [ [ B01.fwd, B02.fwd, B03.fwd, B04.fwd, B05.fwd,
B05.rev, B04.rev, B03.rev, B02.rev, B01.rev ],
[ B01.fwd, B04.fwd ],
[ B04.rev, B01.rev ] ]
Note aside, this shows one issue with encoding the direction in the graph, namely that the reversing block in shuttle mode is going to have at least 3 states: forward, stopped, and reverse.
And that can also be the case for other blocks -- for example imagine a mid station on the shuttle route where the engine enters the blocks and stops before continuing. Do we want to encode the fact the engine is stopped? E.g. is the graph “B.fwd, B.stopped, B.fwd”? That’s why not encoding the direction may make the programming easier -- and in fact in the Conductor 1 test I did with the new syntax, that was simply handled by having the one block in the block list, and then 2 or 3 rules for “Block forward vs Block stopped vs Block reverse” yet there were some clear confusion in that case, so we’ll need to re-evaluate that further. The confusion is that we know the train is in “block B”, but we need rules for “enter block B forward” as well as “enter block B stopped” because in the prototype, changing direction also meant re-entering the rule set as it is defined for “block + direction”.
The bottom line is that right now I’m not satisfied with either the mode from Conductor 1 (linear block list with separate rules), or the mode from the Groovy DSL (linear block list that includes rules). Let’s resume the limitations which are not solved yet:
- It cannot be a linear block list, it has to be a directed cyclic graph.
- One thing I had envisioned at the beginning of Conductor 2 and not present here is “automating” transitions in the graph by indicating which turnouts sit on the edges between the nodes. We can agree that it is not the role of the sequence manager to align any turnout.
- The direction through a node is irrelevant as far as tree traversal is involved.
- But… for automated security checks, the direction of the engine when entering a graph node is actually a good clue that we’re progressing as expected.
- Rules separated from the graph nodes can be confusing to read, whereas rules within the graph node description make the graph confusing the read.
Problem 3: Does direction matter?
So here’s a thought which is somewhat underlined above: we don’t need the engine direction to be constant. E.g. “B04.fwd” is just an indication of the desired state when entering the block. A good part of having the sequence is to have automatic validation and early error detection. We’ll detect timeouts -- too long to change blocks is an error. Similarly, when the next expected block(s) activate, we can check the engine direction and use it as a signal we’re on the right part of the graph. That makes sense for a shuttle sequence manager -- we expect to enter in one direction in one block, and later we expect to enter it in the reverse direction.
Limiting the direction to only the enter event thus clears out the issue of reversing blocks -- we only care how we enter that block. It also solves the problems with mid stations -- a train can have any number of stops or even directions changes once inside that block.
That would also solve the issue with the Conductor 1 prototype: if we have a block graph listing “B04.fwd”, we can have a unique rule set for “B04.fwd”. It does not mean that the train can only go forward in that rule set. In fact at that point “B04.fwd” becomes a semantic label that just happens to link a specific graph node with a specific rule set.
Now I see how I could make the graph more generic: we define a pattern for the graph nodes, which is <sensor>.<direction>.<extra-id>. The “extra id” exists to make node labels unique. Say for example we want to automate a shuttle that goes back and forth thrice between 2 mid stations, we could write it as such:
B1.f -> B2.f -> B3.f -> B2.r -> B3.f -> B2.r -> B3.f -> B4.f -> …
That would represent a train that goes from B2 to B3 and back and forth twice before continuing. Even though we have directions, the graph labels are not unique, so we can add indices or any semantic names:
B1.f -> B2.f.1 -> B3.f.1 -> B2.r.2 -> B3.f.2 -> B2.r.3 -> B3.f.3 -> B4.f -> …
The “.2” and “.3” indices are purely semantic and could be words or anything else.
The next step is that rules would be defined for each of these labels. If rule sets need to be shared, we should be able to say that e.g. “B2.r.2” and “B2.r.3” do the same thing.
Now that we agree that these are labels, we can argue again on having the travel direction in the node name. Is it useful? Let’s consider this:
- Option 1: The node name is “free” as long as node names are unique.
- Option 2: The node name is an encoding of <Sensor[.direction][.unique_id]>.
If we do option 1, we need to indicate the Block/Sensor somewhere else -- that can be a property in the node rules. If we do indicate the direction, it is optional and used only to clear ambiguity; if we want to use it to enforce a sanity check when entering the node, then it could also be a property in the node rule.
Problem 4: How do events work?
The previous section points to using a “graph description” which describes the graph followed by individual rule sets for each graph node. Each node must have a unique-enough name that can be referenced in the rule set.
At that point, vocabulary must matter: a “block” describes a physical entity backed by a sensor, whereas a “node” represents one entity in the graph. Since we are building shuttle sequences, some blocks will appear either once or multiple times in the graph, and each time they will be represented by different nodes each with their unique label. Rule sets are associated with a specific node.
As far as describing events, there are 2 possibilities:
- In the initial groovy DSL, each node’s rule set was a closure attached to a “block.direction” verb. The closure itself contained 2 kind of statements:
- Actions (throttle actions, etc).
- “After” delayed rule blocks.
- Block-related events: onStart, onEnter.
- In the Conductor 1 revamp, I experimented with a different syntax:
[Enter | Block] <SensorName> <Direction> { rules }
The first groovy DSL was a bit ill-defined. For example, what does it mean to put actions directly in the rule set? When are they executed? The block related events were supposed to clarify that:
- onStart is executed when the route starts. Only one block rule can contain onStart, and it becomes the “default” initial starting point of the graph. But what happens if that’s not how the graph has been defined? This can be inconsistent.
- onEnter is executed only when a train enters the block. So what happens to “after” delayed actions in an onEnter rule?
- onExit was implicitly defined yet not used.
To be clear, the original intent was that the Groovy DSL scope would have properties and action executed when entering the block. So for example “speed = N” or any unqualified “after” delayed timer was meant to be equivalent to placing them in an “onEnter” scope. Except I them moved to a syntax where I had essentially: “speed = N” (set the speed when entering the block), onEnter { initial actions }, after { delayed action }.
The “speed = N” is basically a shortcut to writing “onEnter { speed = N }”.
The Conductor 1 revamp tried to clarify this a bit:
- There’s no such thing as an “onStart” inside a node rule. Instead there’s “onActivate” at the route level. That’s more logical. There can be only one of these -- we could however accept for convenience there can be multiple and they get all executed in sequence.
- A “Block N rule” means the rule(s) is evaluated any time the train is in that block -- or more precisely anytime that node is the active one in the graph.
- An “Enter N rule” means the rule(s) is evaluated once when a node becomes active in the graph.
- There is no “Exit” rule, although there could be -- in that case it would be evaluated once when a node changes from active to trailing.
- Exiting the block clears the “Enter executed once” flag; similarly entering the block clears the “Exit executed once” flag (so we could have a system where a train flip-flops between 2 nodes)..
- “Block” and “Enter” can be thought of as prefixes or shortcuts to writing “if node N is active”. There could be any number for the same node and they are evaluated in order.
- Semantically, we can imagine all these rules sets could be “unrolled” and written line after line all with a prefix test condition of “is block active”. When we think of it that way, it means that any “after “delayed action will only execute if the train is still in the block when the timer expires and triggers. With some nuances.
- After delayed evaluated:
- For “Block” rules, as long as the train is in the block. As soon as the train leaves the blocks, the after timers are canceled.
- For “Enter” rules, they get triggered once and still execute if the train is in the block when the timer expires. We can think of them as having their own “execute once” flag. As soon as the train leaves the blocks, the after timers are canceled.
- For “Exit” rules, they get triggered once and still execute if the train is not in the block when the timer expires. We can think of them as having their own “execute once” flag. As soon as the train re-enters the block, the after timers are canceled.
I believe that makes the “after delayed” timers more explicit. They are tied to the “scope” of the block being active. If an action must be performed whether the train is or isn’t in the block, then a global timer should be triggered and used.
Whether I use a Groovy DSL or the Conductor 1 revamp, this model is clearly the way to go.
One thing that we’ll not reuse from the Conductor 1 revamp is how the direction was used in the node definition. E.g. in Conductor 1, I had rule sets prefixed with e.g. “Enter B320 Forward” or “Enter B320 Stopped”... the direction condition was to be the “live” one at evaluation time, which leads to a confusion when I need to create a move-stop-at-station-continue script as in this case we get “B320 Forward / B320 Stopped / B320 Forward”. As discussed in the previous section, this is not descriptive enough. Instead the rule sets are going to be prefixed with a unique name that matches the graph description, so for example we’ll call that node “B320.fwd” to indicate this is an action when we enter the B320 in forward mode, regardless of what happens after it has been entered. Once the node is active, it remains active as long as the same block is active.
We still have 2 models to choose from:
- In the Conductor 1 revamp, we have all rule sets in parallel at the top level. E.g. “Enter B320 forward” and “Block B320 forward” are two separate definitions.
- In the old Groovy DSL, we have scoped rule sets with everything per node. E.g. in this case we would have one scope for “B320.forward” containing an “onEnter” event and one an “onBlock” event.
That latter scoped syntax seems more appropriate for a Groovy DSL. The only difference is:
- The “speed = N” property was supposed to be a shortcut to writing “onEnter speed = N”. But then when it’s followed by an onEnter block, it seems odd. So might as well write the full onEnter version.
- Same for the after delayed timer.
- Basically all rules should appear inside either “onEnter / onBlock / onExit”, to make it clear what’s happening -- and the onExit block will not even be implemented at first as it didn’t seem very useful.
- The only property I’m considering is to indicate the entering direction, and even that seems pointless. We don’t need it.
Let’s recap what was said on the node travel direction earlier and why we don’t need it:
- Travel direction within the block is not constant. A train can stop and go, or reverse. Thus knowing the “entering direction” is not a usable signal representative of the train travel within the block.
- For error recovery, we need to understand which node to select in the graph to recover from a static starting point. Which means the train will be stopped and will not have a running direction. Thus knowing the “entering direction” of the node is not a usable signal..
- Progressing in the graph (going from one node to one of its edge nodes) is going to be based solely on which block becomes active next. The block sensor is all the information needed here, the “entering direction” is not a signal used in that decision.
- The only case where we could potentially use the “entering direction” is to set up some kind of alarm mechanism, e.g. defaulting the run route if we detect a block becomes active with the train in a different direction than the one indicated in the node.
- That would be a severe error condition indicating either a drastic programming fault in the script, or indicating that the manager is out of sequence and the wrong node is active in the graph.
- If we really want to enforce that, we might as well have some kind of validation rule in the “onEnter” case. For example:
onEnter { Throttle != Forward → ThisRoute.Error = true }